Updates
|
• Twice a year, we host the Bay Area Speech AI for Health, Education, and HCI Workshop, convening leaders from academia, industry, venture capital, healthcare, and education. Our goal is to shape the future of human-centered speech intelligence — connecting fundamental research with real-world systems and societal impact. We welcome researchers, practitioners, founders, and investors to join, present, or collaborate. Please feel free to contact me. https://sites.google.com/berkeley.edu/bair-speech-ai-workshop
|
Research
|
I'm interested in research questions that will still matter five years from now.
Currently, I work on the following areas:
(1) Human-Centered Artificial Intelligence Beyond Scaling Limits
Developing human-centric learning mechanisms and interactive labeling pipelines to extract strong supervision from imperfect and limited data. The goal is to enable intelligence-aware scaling—where learning is guided by insight, not just data volume.
(2) Modeling Human Verbal Behavior for Cognitive and Clinical Insights
Developing computational models to infer cognitive states from verbal behavior (e.g. dy(i)sfluency), focusing on voice-based biomarkers for speech and language disorders (e.g., Primary Progressive Aphasia, Dyslexia), and standardizing them for clinical integration.
(3) Condition-Specific AI for Diagnosis, Prevention, and Therapy
Designing precision-driven, condition-specific AI systems for early detection, risk prediction, and therapeutic support in speech and language disorders—aiming for clinical and educational deployment to support decision-making at both individual and population levels.
(4) Universal Language Function Evaluation at Scale
Building a unified platform for large-scale evaluation of language function across educational and clinical settings—combining pronunciation feedback, cognitive assessment, and other speech tasks in a synergistic framework. Also exploring HCI-driven service agents with accessible, interpretable, and socially aware interfaces to support longitudinal use.
|
News
• Starting from 2025, as approved by the California State Government, public schools will adopt our language screener, where I developed the first and state-of-the-art speech dysfluency transcriber [UDM][SSDM], serving 1 million kids! See reports.
|
Selected Publications
|
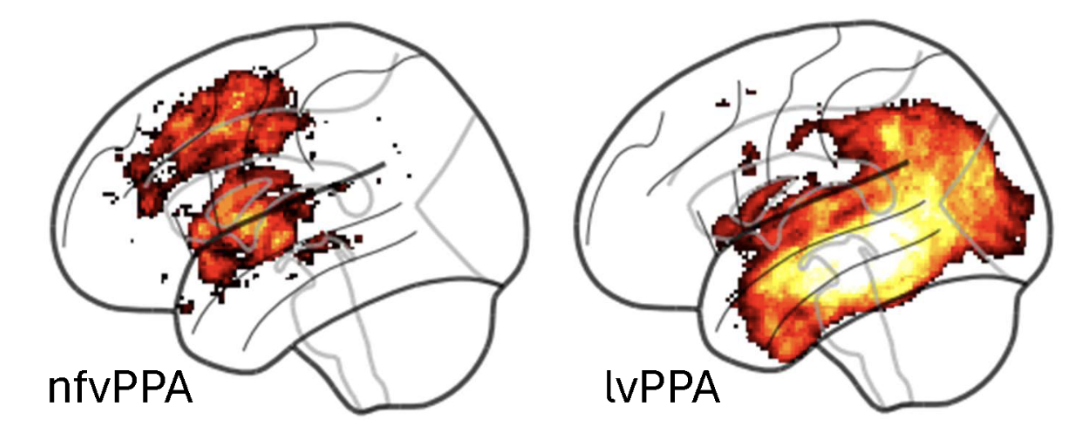
Automated Lexical Dysfluency Analysis to Differentiate Primary Progressive Aphasia Variants
Jet M.J. Vonk* (co-first), Jiachen Lian* (co-first), Zoe Ezzes, Lisa Wauters, Cheol Jun Cho, Brittany T. Morin, Rian Bogley, Diana Rodriguez, Boon Lead Tee, Jessica DeLeon, Zachary Miller
, Maria Luisa Mandelli, Gopala Krishna Anumanchipalli* (co-last), Maria Luisa Gorno-Tempini* (co-last)
AAIC (Alzheimer's Association International Conference) 2025 (Oral Presentation). AI models assist doctors in diagnosing speech language disorders with high clinical alignment
|

|
Automatic Detection of Articulatory-Based Disfluencies in Primary Progressive Aphasia
Jiachen Lian, Xuanru Zhou, Chenxu Guo, Zongli Ye, Zoe Ezzes, Jet
Vonk, Brittany Morin, David Baquirin, Zachary Miller, Maria Luisa Gorno Tempini
and Gopala
Krishna Anumanchipalli,
2025 JSTSP An efficient AI Agent for Language Screening and Spoken Language Learning.
[Project Page]
|
|
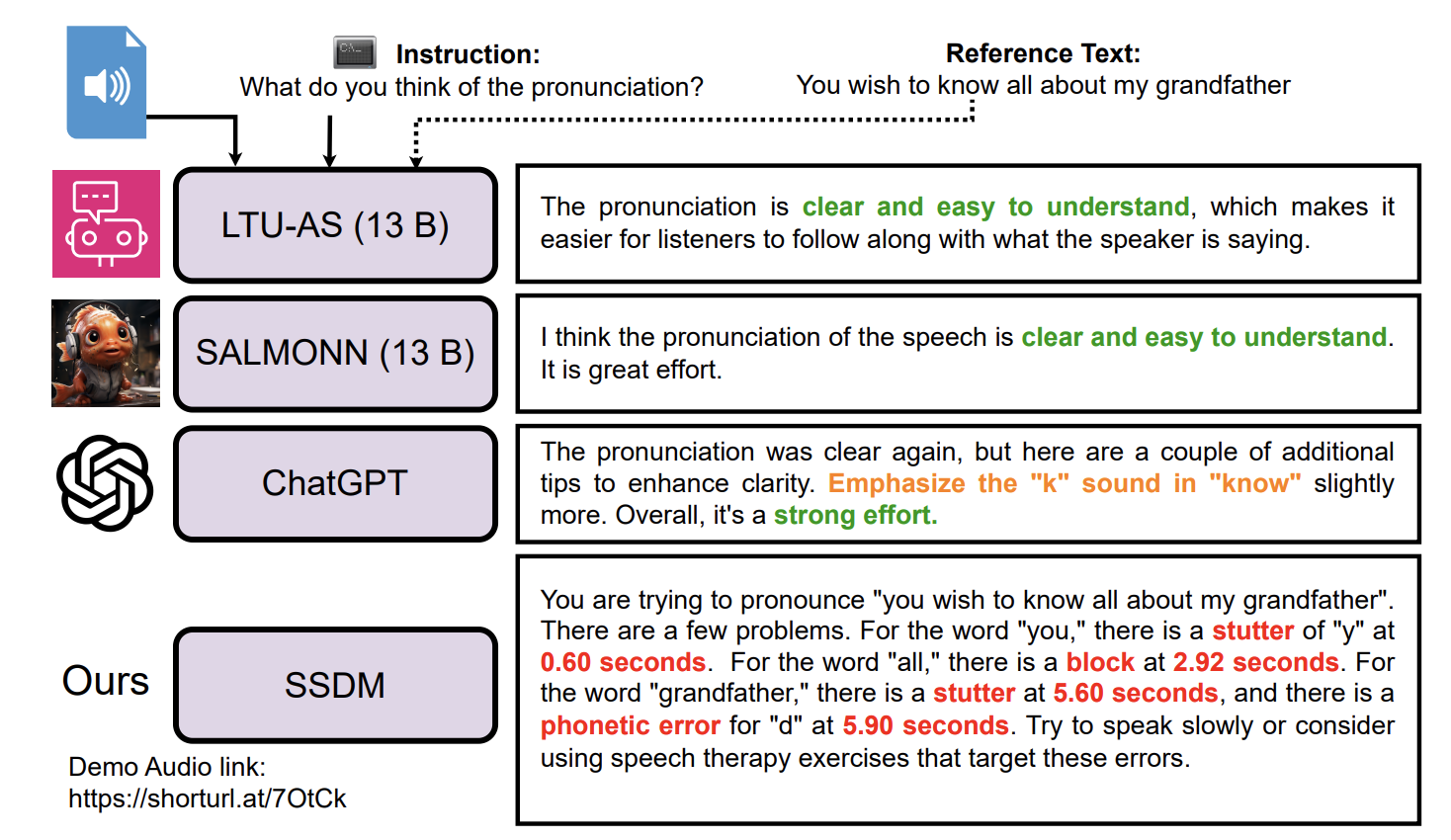
SSDM: Scalable Speech Dysfluency Modeling
Jiachen Lian, Xuanru Zhou, Zoe Ezzes, Jet
Vonk, Brittany Morin, David Baquirin, Zachary Miller, Maria Luisa Gorno Tempini
and Gopala
Krishna Anumanchipalli,
2024 NeurIPS. An AI Agent for Speech Therapy and Spoken Language Learning. A foundation model for scientific research, engineering deployment and business development .
[Project Page] ( NeurIPs Scholar Award )
|
|
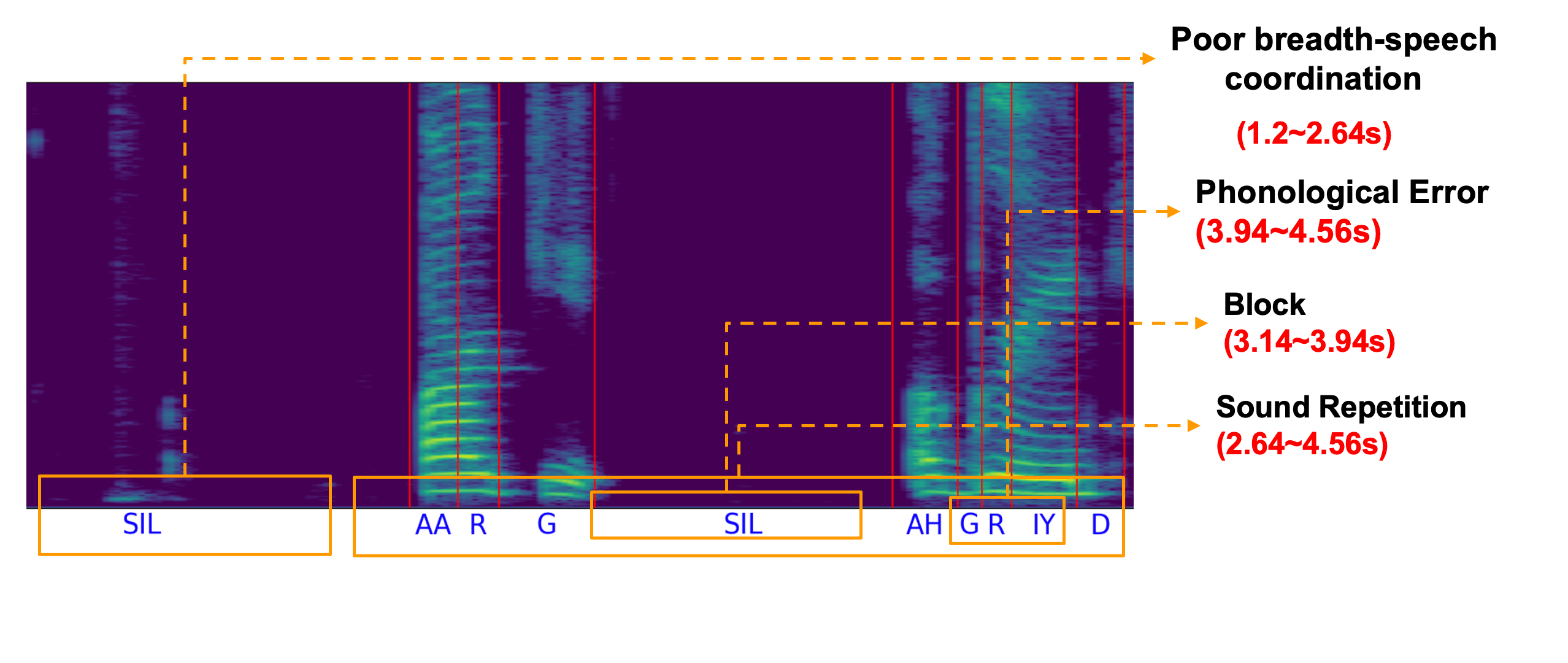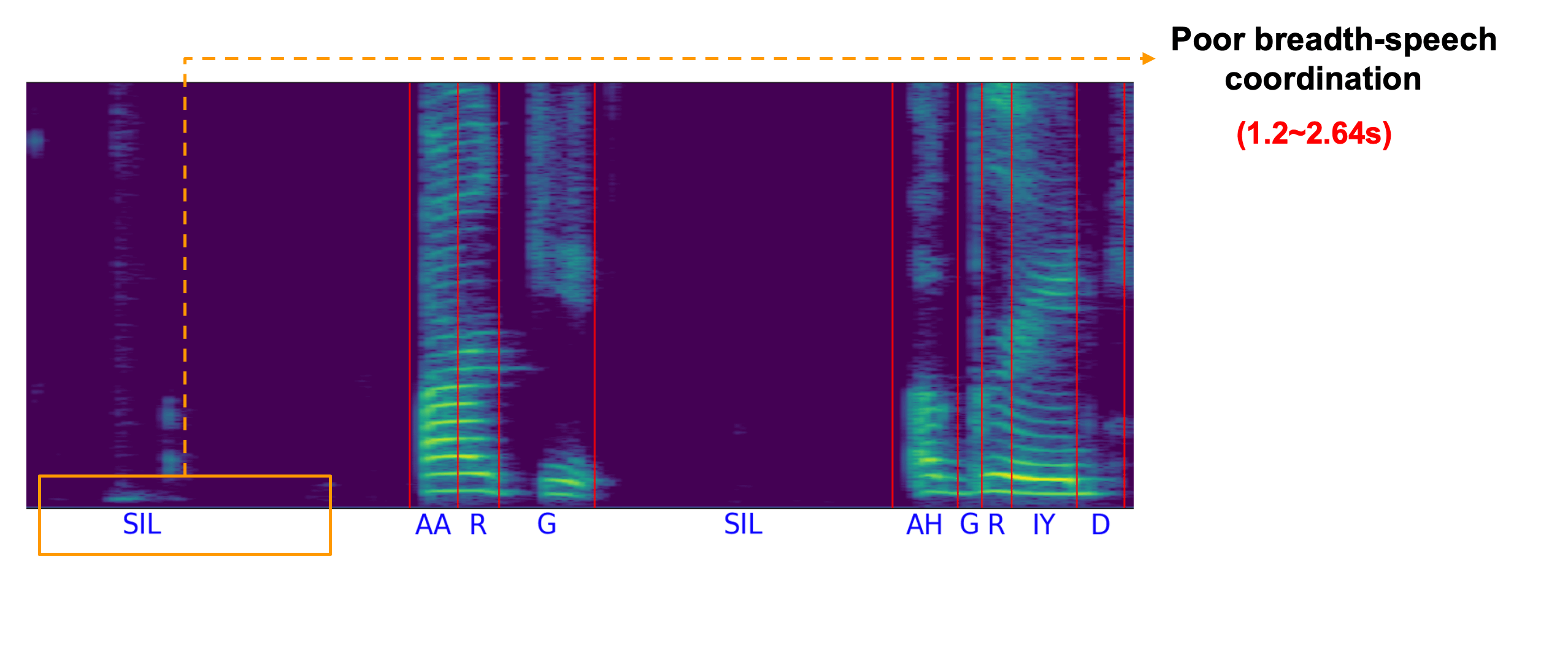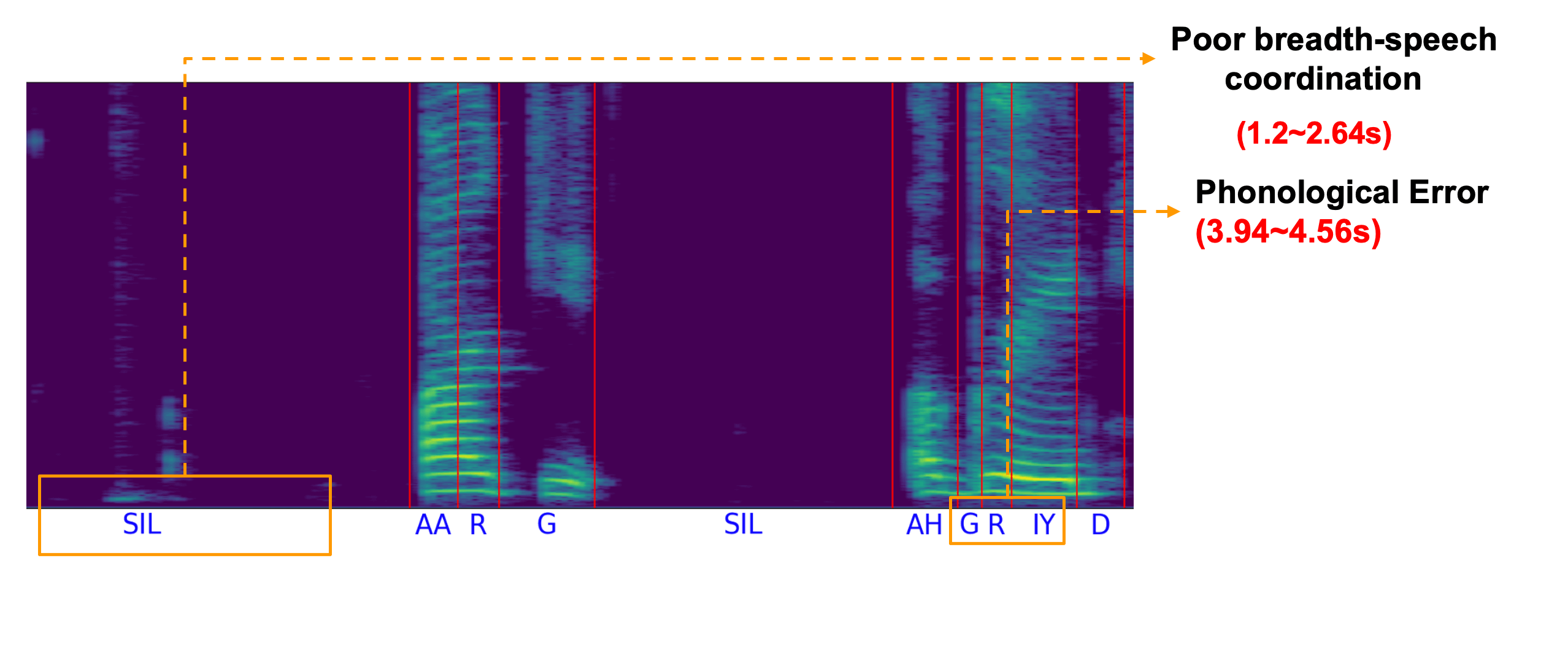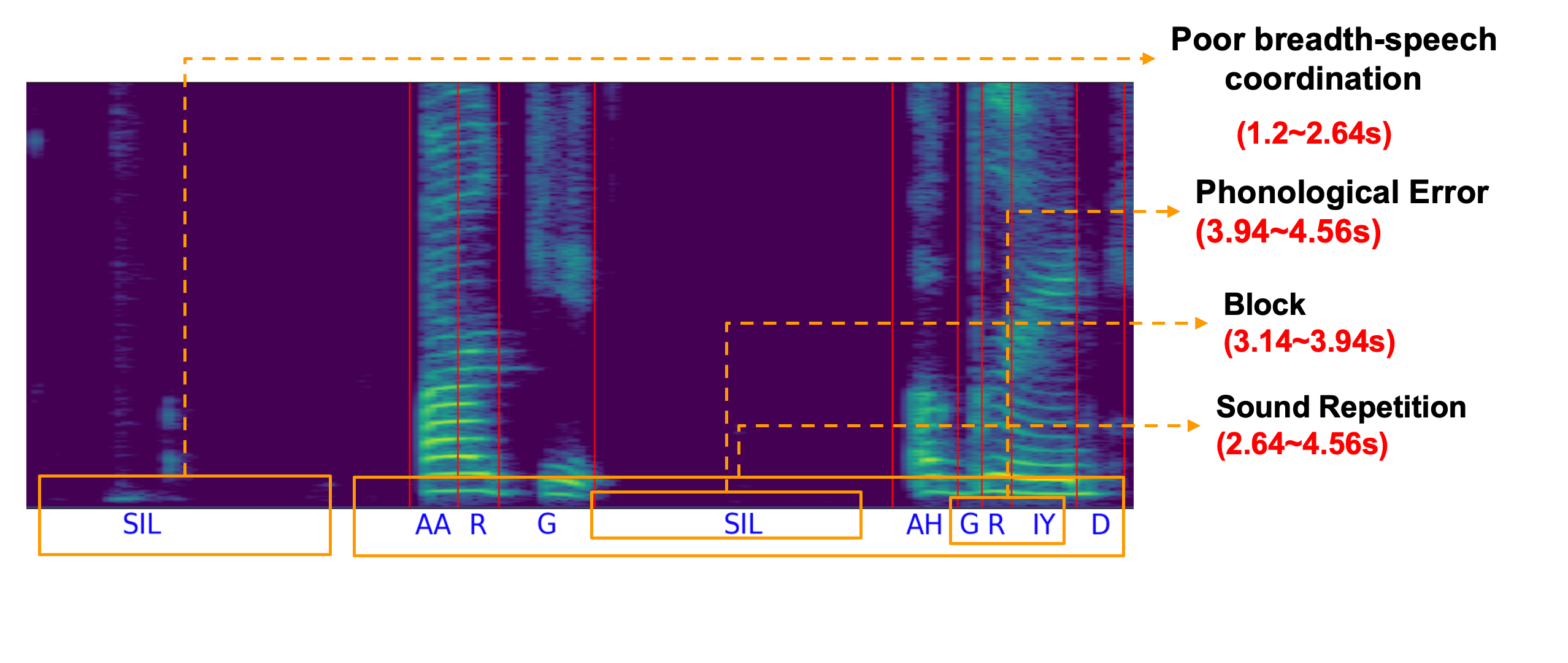
Unconstrained Dysfluency Modeling for Dysfluent Speech Transcription and Detection
Jiachen Lian,
Carly Feng,
Naasir Farooqi,
Steve Li,
Anshul Kashyap,
Cheol Jun Cho,
Peter Wu,
Robbie Netzorg,
Tingle Li,
and Gopala
Krishna Anumanchipalli,
2023 ASRU (Best Paper Nomination ). First work to detect both type and time of dys(dis)fluencies.
2024 Sevin Rosen Funds Award
|
|
Industrial
Meta AI, CA, USA
Visiting Researcher • Sep 2024 to Now
With: Abdelrahman Mohamed
|

|
|
|
|
Meta AI, CA, USA
Research Intern • May 2022 to Dec. 2022
With: Alexei Baevski, Wei-Ning Hsu, Michael Auli
|
|
|
Speech and NLP Group, Tencent AI Lab(American) , WA, USA
Research Intern • April 2021 to May 2022
With: Chunlei Zhang, Dong Yu
|

|
|
Education
UC Berkeley, U.S.
Ph.D. in EECS • Aug. 2021 to Present
|

|
|
Carnegie Mellon University, U.S.
M.S. in ECE • Sept.2019 to Dec. 2020
|

|
|
Zhejiang University, China
B.Eng. in EE • Aug. 2015 to June 2019
|

|
|
Awards
2025 Radical Venture AI Founders Grant (350k$)
2024 NeurIPs Scholar Award
2024 Sevin Rosen Funds Award
2023 ASRU Best Paper Finalist
2021 Berkeley EECS Fellowship
|
|
|


