Research
|
I'm interested in research questions that will still matter five years from now.
I build interpretable, human-centered foundation models — and the systems and robots that bring them into the real world.
(1) Interpretable-by-design, mechanistically grounded foundation models
I develop foundation models whose internal representations are structured and inspectable, and whose reasoning, planning, and dynamics can be examined and controlled.
(2) Human-AI collaboration and deployment in high-stakes healthcare settings
I build collaborative, deployed systems for precision and public health — speech and language disorders such as dyslexia and primary progressive aphasia, and population-level language screening.
(3) Human-centered speech AI systems
I build speech AI that is grounded in human cognition and physiology (perception, production, physics) and that keeps people in the loop through interactive labeling, feedback, and supervision.
(4) Controllable robots and inverse problems
I work toward robots whose actions we can steer, predict, and understand.
|
News & Updates
|
• [Oct 2024] As approved by the California State Government, starting from 2025 public schools will adopt our language screener, where I developed the first and state-of-the-art speech dysfluency transcriber [UDM][SSDM], serving 1 million kids! See reports.
• [Oct 2025] Twice a year, we host the Bay Area Speech AI for Health, Education, and HCI Workshop, convening leaders from academia, industry, venture capital, healthcare, and education. Our goal is to shape the future of human-centered speech intelligence — connecting fundamental research with real-world systems and societal impact. We welcome researchers, practitioners, founders, and investors to join, present, or collaborate. Please feel free to contact me. https://sites.google.com/berkeley.edu/bair-speech-ai-workshop
|
|
Selected Academia Publications
|
Human-Centered Speech AI System
|
|
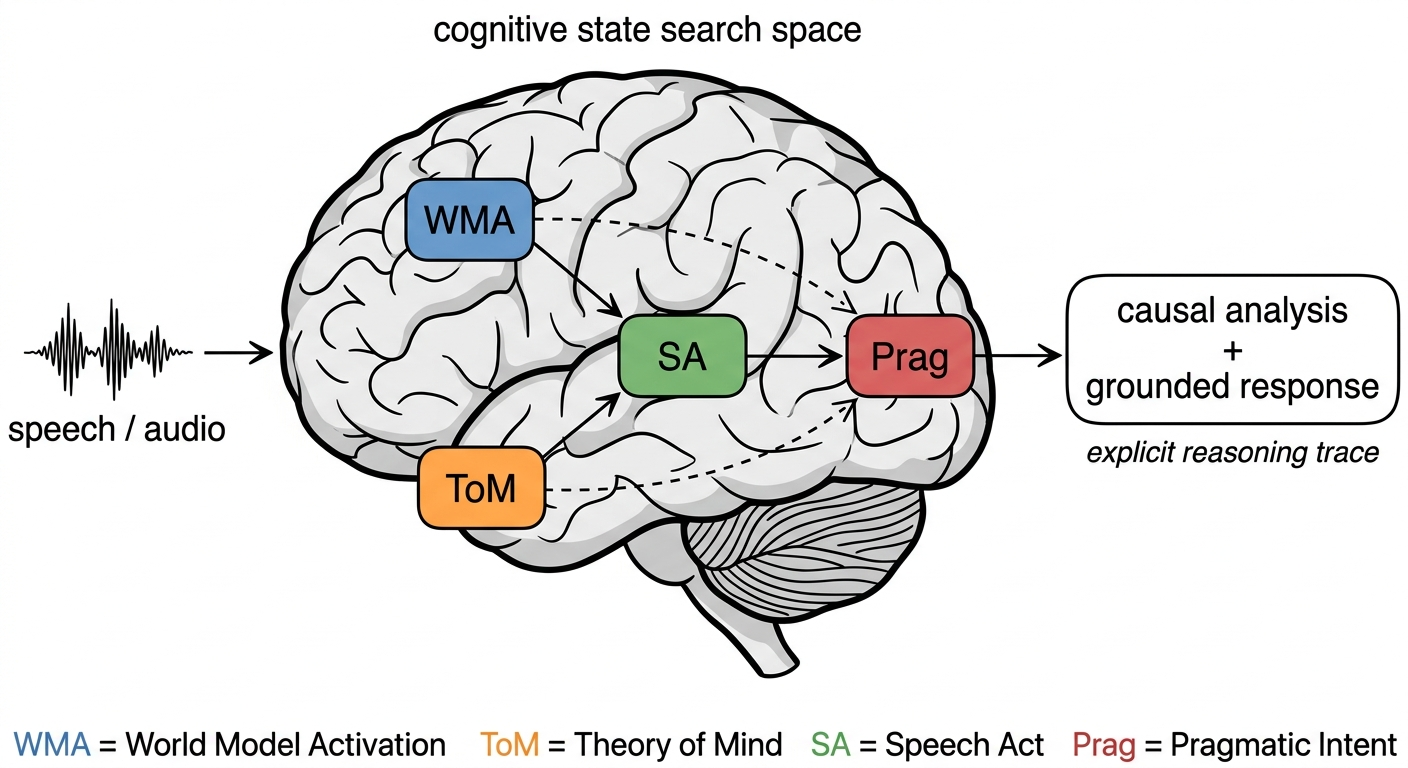
Speech World Model: Causal State-Action Planning with Explicit Reasoning for Speech
Xuanru Zhou* (co-first), Jiachen Lian* (co-first), Henry Hong, Xinyi Yang, and Gopala Krishna Anumanchipalli,
2026 ICLR. The first world model for speech.
|

|
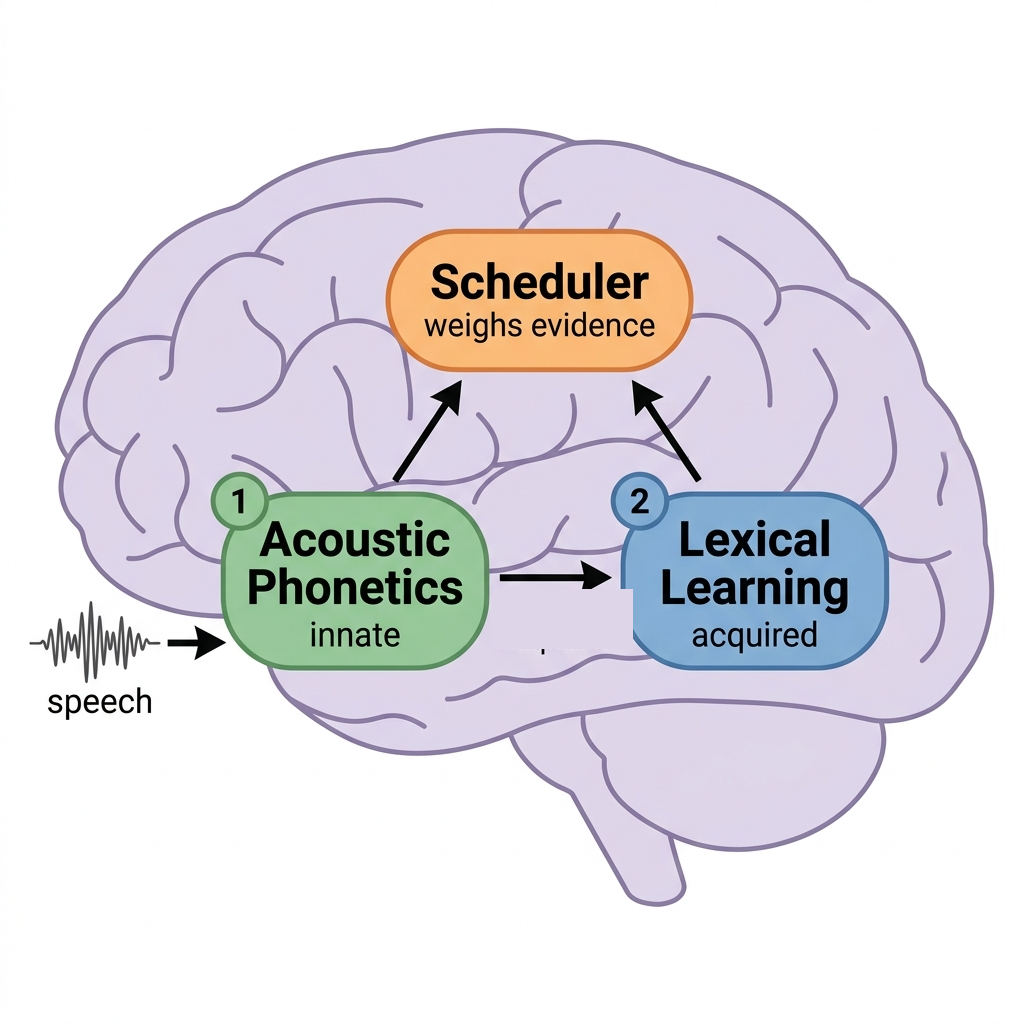
HuPER: A Human-Inspired Framework for Phonetic Perception
Chenxu Guo* (co-first), Jiachen Lian* (co-first), Yisi Liu, Baihe Huang, Shriyaa Narayanan, Cheol Jun Cho, and Gopala Krishna Anumanchipalli,
2026 arXiv. Human-centered design that elicits 100× greater data efficiency than scaling-based methods. Adopted by the Qwen Omni series as its default speech perception framework.
[Code]
[🤗 36,076 downloads]
|
|
AI Healthcare System Design
|
|
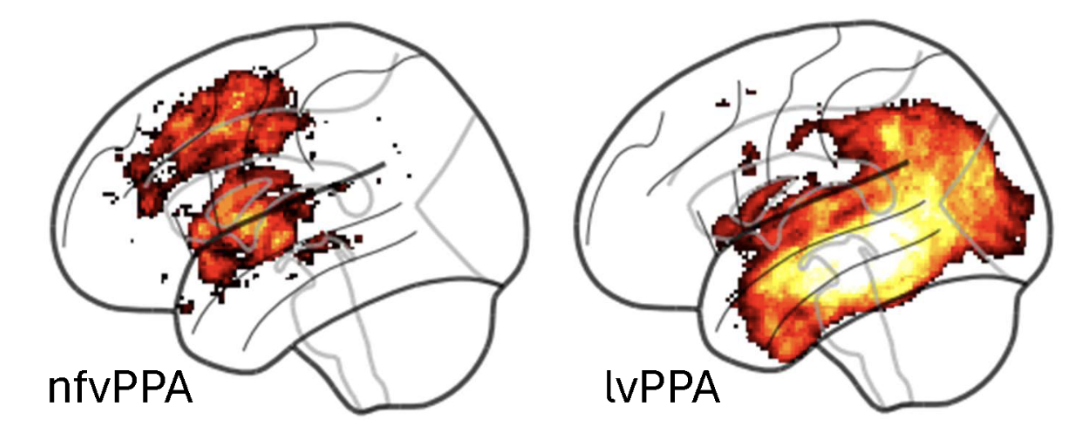
AI-based Speech Error Detection to Differentiate Primary Progressive Aphasia Variants
Jet M.J. Vonk* (co-first), Jiachen Lian* (co-first), G. Lynn Kurteff* (co-first), Cheol J. Cho, Giada Antonicelli, Zoe Ezzes, Lisa D. Wauters, Willa Keegan-Rodewald, Diana Alejandra Rodriguez, Nina Dronkers, Maya L. Henry, Zachary A. Miller, Maria Luisa Mandelli, Gopala K. Anumanchipalli, Maria Luisa Gorno-Tempini
Neurology 2026. Interpretable, expert-level PPA subtype differential diagnosis
|

|
Automatic Detection of Articulatory-Based Disfluencies in Primary Progressive Aphasia
Jiachen Lian, Xuanru Zhou, Chenxu Guo, Zongli Ye, Zoe Ezzes, Jet
Vonk, Brittany Morin, David Baquirin, Zachary Miller, Maria Luisa Gorno Tempini
and Gopala
Krishna Anumanchipalli,
2025 JSTSP An efficient AI Agent for Language Screening and Spoken Language Learning.
[Project Page]
|
|
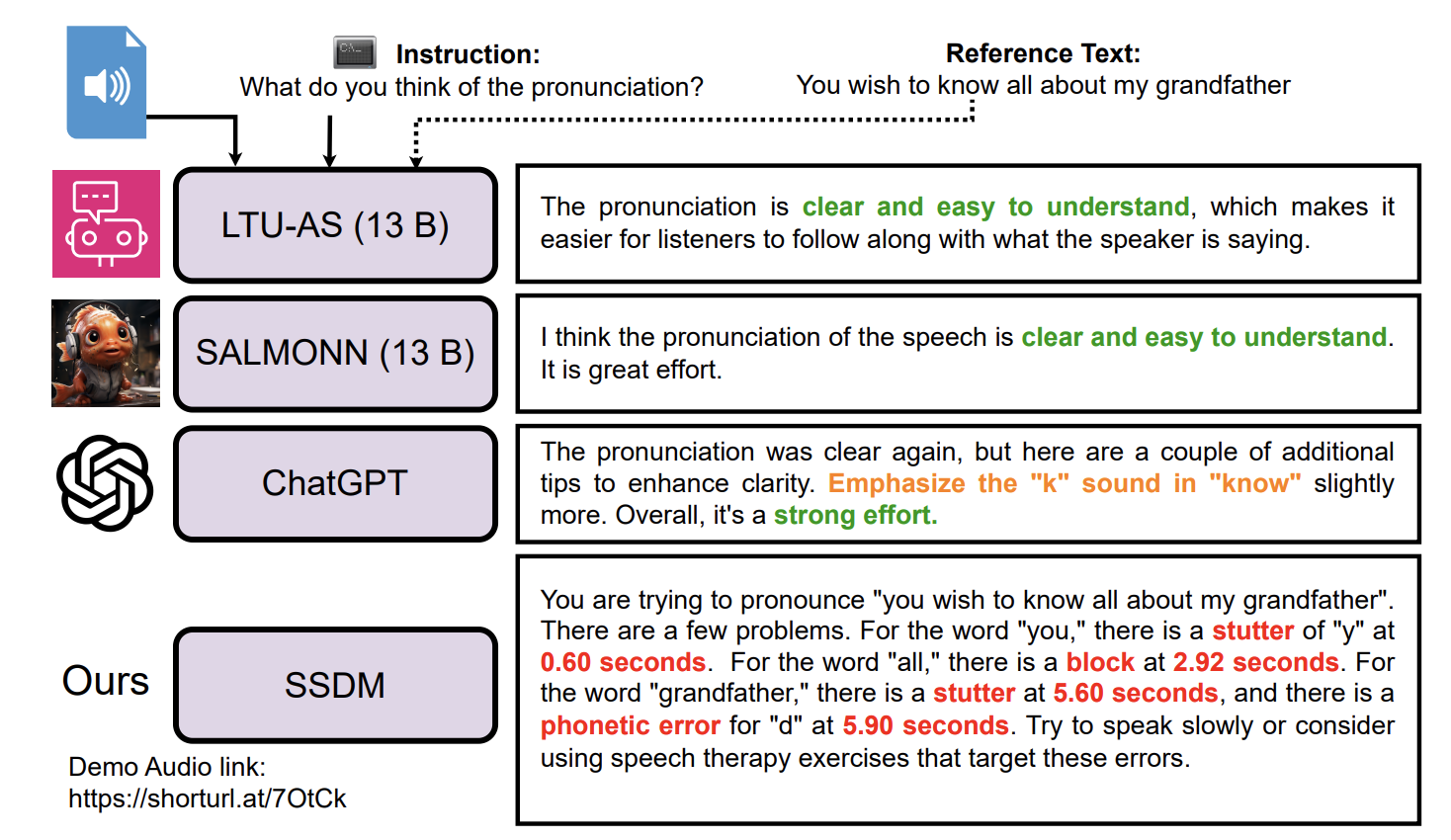
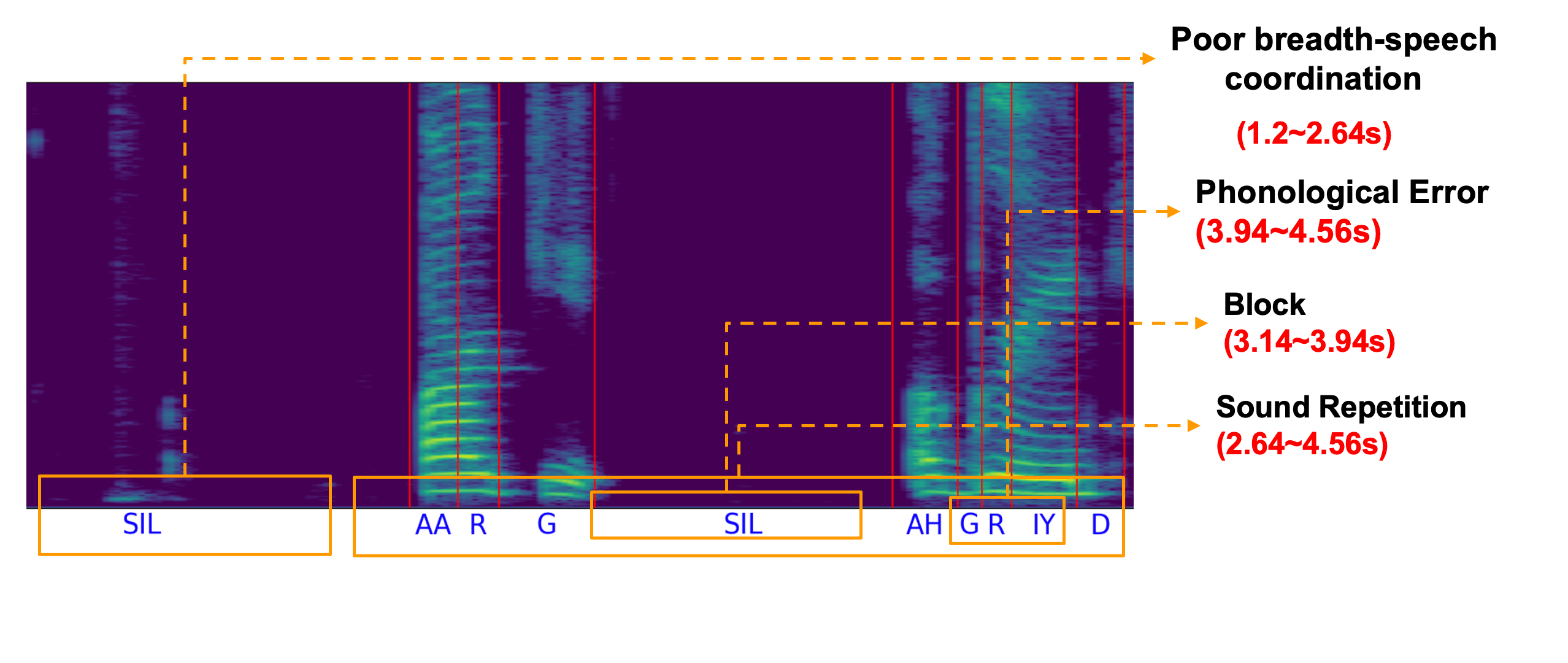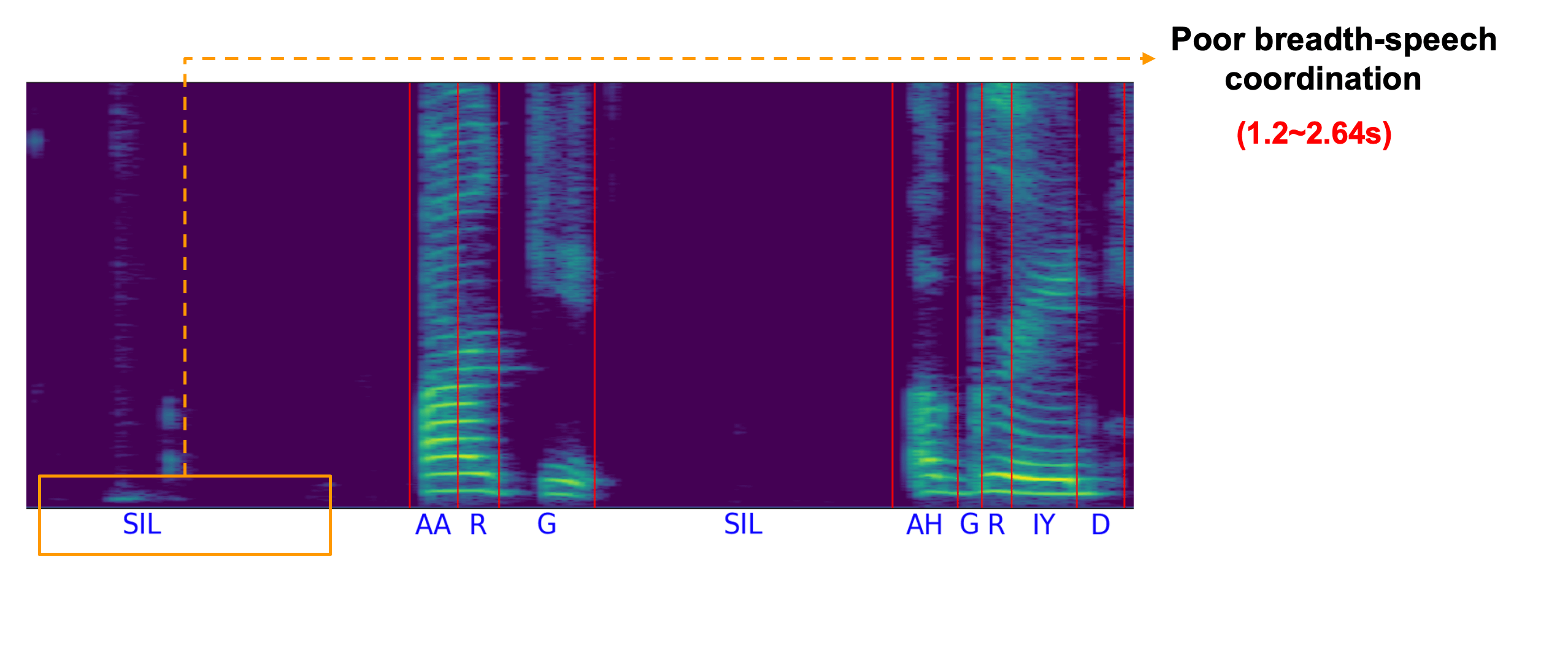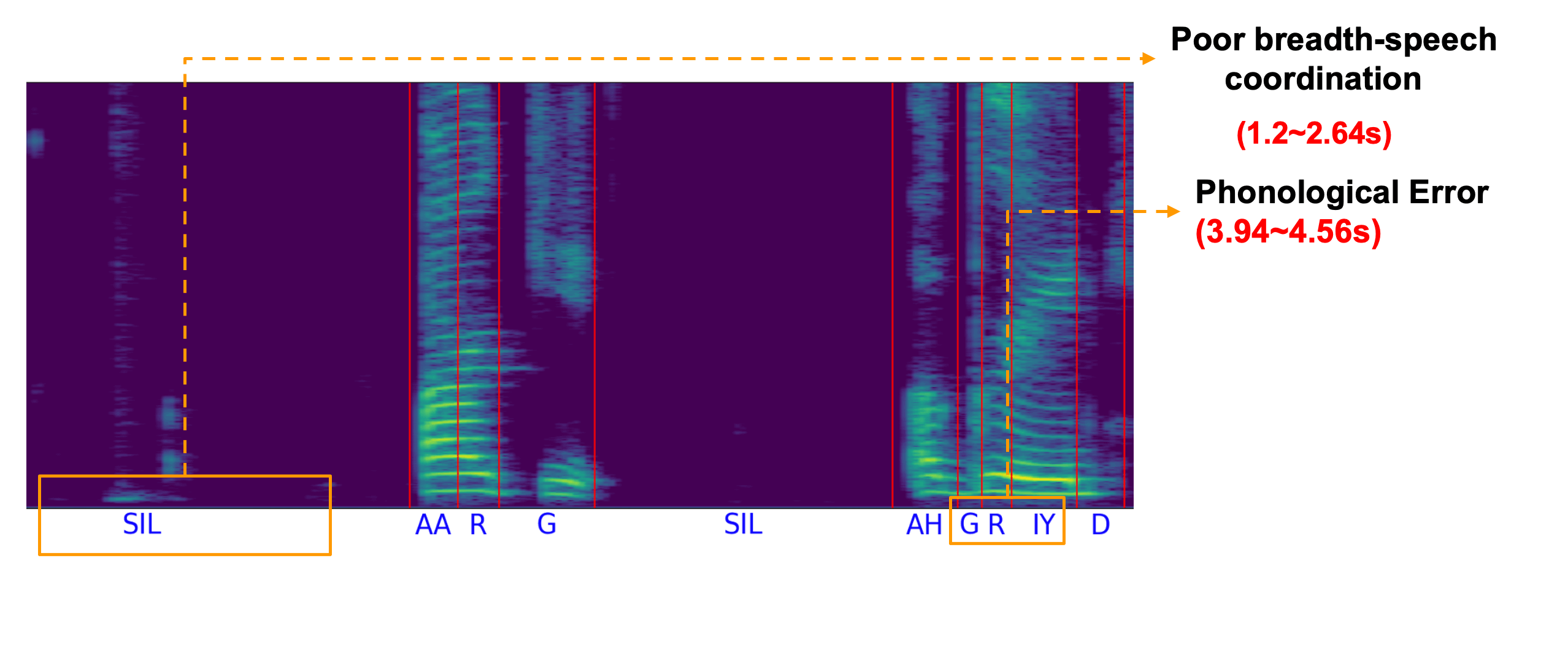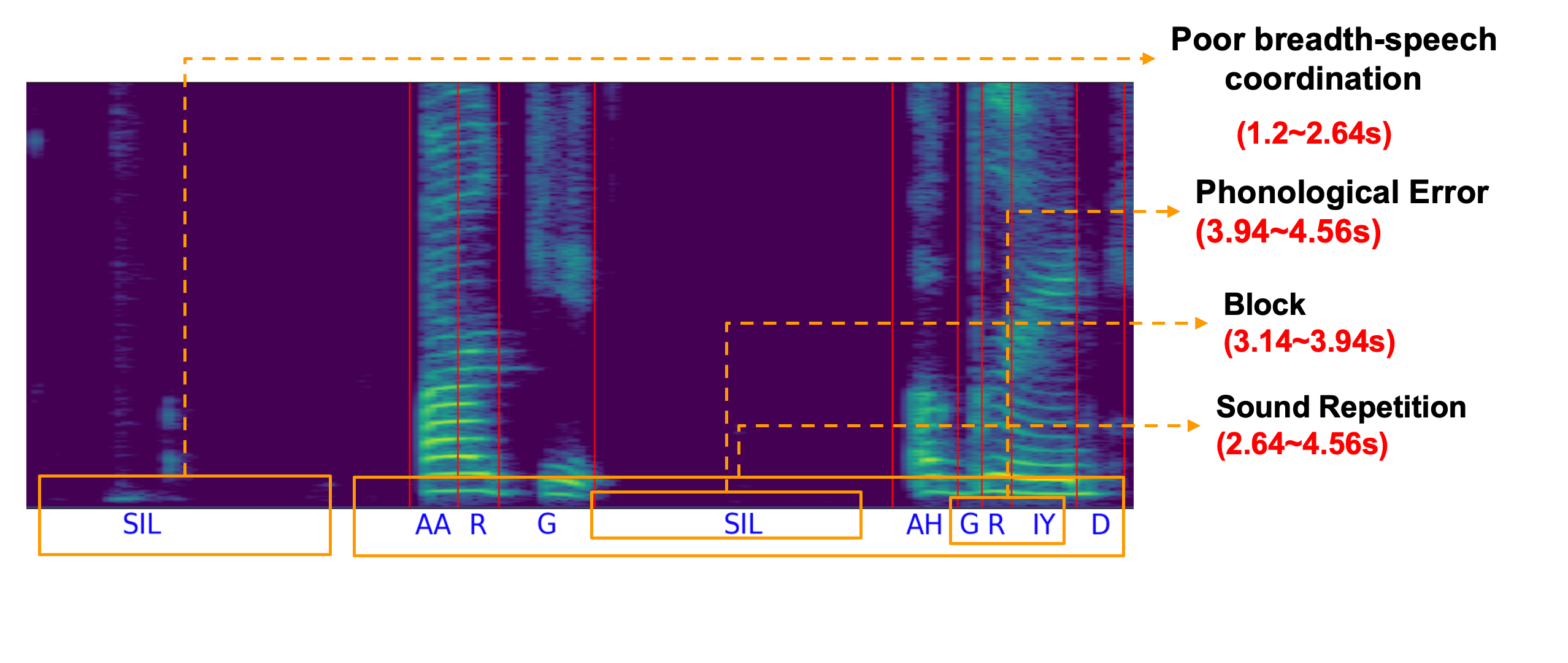
SSDM: Scalable Speech Dysfluency Modeling
Jiachen Lian, Xuanru Zhou, Zoe Ezzes, Jet
Vonk, Brittany Morin, David Baquirin, Zachary Miller, Maria Luisa Gorno Tempini
and Gopala
Krishna Anumanchipalli,
2024 NeurIPS. An AI agent for speech therapy and spoken language learning.
[Project Page] ( NeurIPs Scholar Award )
|
|
Unconstrained Dysfluency Modeling for Dysfluent Speech Transcription and Detection
Jiachen Lian,
Carly Feng,
Naasir Farooqi,
Steve Li,
Anshul Kashyap,
Cheol Jun Cho,
Peter Wu,
Robbie Netzorg,
Tingle Li,
and Gopala
Krishna Anumanchipalli,
2023 ASRU (Best Paper Nomination ). First work to detect both type and time of dys(dis)fluencies.
2024 Sevin Rosen Funds Award
|
|
Industrial
Meta AI, CA, USA
Visiting Researcher • Sep 2024 to June 2026
LLaMA Team (3.2/3.3 post-training; LLaMA 4 duplex pre/post-training, Vision MoE)
|

|
|
|
|
Meta AI, CA, USA
Research Intern • May 2022 to Dec. 2022
With: Alexei Baevski, Wei-Ning Hsu, Michael Auli
|
|
|
Tencent AI Lab, WA, USA
Research Intern • April 2021 to May 2022
With: Chunlei Zhang, Dong Yu
|

|
|
Education
UC Berkeley, U.S.
Ph.D. in EECS • Aug. 2021 to Present
|

|
|
Carnegie Mellon University, U.S.
M.S. in ECE • Sept.2019 to Dec. 2020
|

|
|
Zhejiang University, China
B.Eng. in EE • Aug. 2015 to June 2019
|

|
|
|


